Observed power (or post-hoc power) is the statistical power
of the test you have performed, based on the effect size estimate from your
data. Statistical power is the probability of finding a statistical difference
from 0 in your test (aka a ‘significant effect’), if there is a true difference
to be found. Observed power differs from the true power of your test, because
the true power depends on the true effect size you are examining. However, the
true effect size is typically unknown, and therefore it is tempting to treat
post-hoc power as if it is similar to the true power of your study. In this
blog, I will explain why you should never calculate the observed power (except
for blogs about why you should not use observed power). Observed power is a
useless statistical concept, and at the end of the post, I’ll give a suggestion
how to respond to editors who ask for post-hoc power analyses.
Observed (or post-hoc) power and p-values are directly related. Below, you can see a plot of observed
p-values and observed power for 10000
simulated studies with approximately 50% power (the R code is included below). It looks like a curve, but the
graph is basically a scatter plot of a large number of single observations that
fall on a curve expressing the relation between observed power and p-values.

Below, you see a plot of p-values
and observed power for 10000 simulated studies with approximately 90% power.
Yes, that is exactly the same curve these observations fall on. The only
difference is how often we actually observe high p-values (or have low observed power). You can see there are only a
few observations with high p-values
if we have high power (compared to medium power), but the curve stays exactly the
same. I hope these two figures drive home the point of what it means that p-values and observed power are directly
related: it means that you can directly convert your p-value to the observed power, regardless of your sample size or
effect size.

Let’s draw a vertical line at p = 0.05, and a horizontal line at 50% observed power. We can see
below that the two lines meet exactly at the line visualizing the relationship
between p-values and observed power. This means that anytime you observed a p-value of p = 0.05 in your data, your observed power will be 50% (in infinite sample sizes, in t-tests - Jake Westfall pointed me to this paper showing the values at smaller samples, and for F-tests with different degrees of freedom).

I noticed these facts about the relationship between
observed power and p-values while
playing around with simulated studies in R, but they are also explained in Hoenig& Heisey, 2001.
Some estimates (e.g., Cohen, 1962) put the average power of
studies in psychology at 50%. What observed power can you expect, when you
perform a lot of studies which have a true power of 50%? We know that the p-values we can expect should be split
down the middle, with 50% being smaller than p = 0.05, and 50% being larger than p = 0.05. The graph below gives the p-value distribution for 100000 simulated independent t-tests:

The bar on the left are all (50.000 out of 100.000) test
results with a p < 0.05. The
observed power distribution is displayed below:
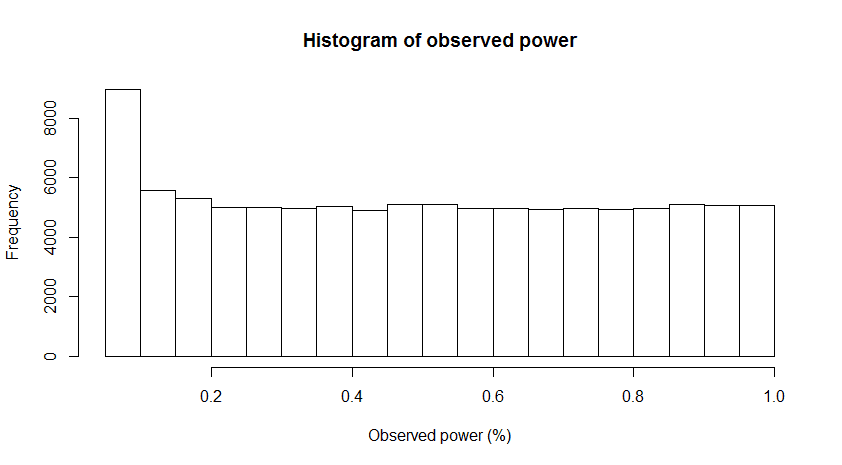
It is clear you can expect just about any observed power
when the true power of your experiment is 50%. The
distribution of observed power changes from positively skewed to negatively
skewed as the true power increases (from 0 to 1), and when power is around 50% we
observe a tipping point where there is a switch from a negatively skewed
distribution to a positively skewed distribution. With slightly more power
(e.g., 56%) the distribution becomes somewhat U-shaped, as can be seen in the figure
below. I’m sure a mathematical statistician can explain the why and how of this
distribution in more detail, but here I just wanted to show what it looks like,
because I don’t know of any other sources of information where this
distribution is reported (thanks to a reader, who in the comments points out Yuan & Maxwell, 2005 also discuss observed power distributions).

Editors asking for
post-hoc power analyses
Editors sometimes ask researchers to report post-hoc power
analyses when authors report a test that does not reveal a statistical
difference from 0, and when authors want to conclude there is no effect. In
such situations, editors would like to distinguish between true negatives
(concluding there is no effect, when there is no effect) and false negatives
(concluding there is no effect, when there actually is an effect, or a Type 2
error). As the preceding explanation of post-hoc power hopefully illustrates, reporting post-hoc power
is nothing more than reporting the p-value
in a different way, and will therefore not answer the question editors want to know.
Because you will always have low observed power when you
report non-significant effects, you should never perform an observed or
post-hoc power analysis, even if an editor requests it (feel free to link to
this blog post). Instead, you should explain how likely it was to observe a
significant effect, given your sample, and given an expected or small effect
size. Perhaps this expected effect size can be derived from theoretical
predictions, or you can define a smallest effect size of interest (e.g., you
are interested in knowing whether an effect is larger than a ‘small’ effect of d < 0.3).
For example, if you collected 500 participants in an
independent t-test, and did not
observe an effect, you had more than 90% power to observe a small effect of d = 0.3. It is always possible that the
true effect size is even smaller, or that your conclusion that there is no
effect is a Type 2 error, and you should acknowledge this. At the same time,
given your sample size, and assuming a certain true effect size, it might be most probable that there is no effect.
1. I would like to add that post-hoc power for a single statistical test is useless. However, post-hoc power provides valuable information for a set of independent statistical tests. I would not trust an article that reports 10 significant results when the median power is 60%. Even if median power is 60% and only 60% of results are significant, post-hoc power is informative. It would suggest that researchers have only a 60% chance to get a significant effect in a replication study and should increase power to make a replication effort worthwhile.
ReplyDelete2. The skewed distribution of observed power for true power unequal .50 was discussed in Yuan and Maxwell (2005) http://scholar.google.ca/scholar_url?url=http://irt.com.ne.kr/data/on_the_pos-ences.pdf&hl=en&sa=X&scisig=AAGBfm1W3wVWuS3MecdWMU0dEkoVal4U3A&oi=scholarr&ei=wZOUVNuXD67IsASZ-YKIDQ&ved=0CB0QgAMoADAA
3. It was also discussed in Schimmack (2012) as a problem in the averaging of observed power as an estimate of true power and was the reason why the replicability index uses the median to estimate true (median) power of a set of studies. http://r-index.org/uploads/3/5/6/7/3567479/introduction_to_the_r-index__14-12-01.pdf
You are right to focus attention on the effect size rather than power as an argument for "proving the null" (even if only suggestively); but we have a long way to go in agreeing what effect size is indeed too small to matter, when discredited examples like Rosenthal's aspirin study keep circulating.
ReplyDeleteI would go further and say that a priori power analysis is useful for a direct replication; has only suggestive value for a conceptual replication; and is near-useless for the 90% (?) of published research that rests on finding a novel effect, even one such as a moderation by context that may include an incidental replication (the power needed for the interaction will have little to do with that needed for the main effect).
Hi Roger, could you elaborate a little on "discredited examples like Rosenthal's aspirin study"? I am aware of the paper you're referring to but not clear on what is discredited.
DeleteThe way the effect size was calculated by Rosenthal has been discredited (well it may be harsh to say "discredited"). See: http://www.researchgate.net/publication/232494334_Is_psychological_research_really_as_good_as_medical_research_Effect_size_comparisons_between_psychology_and_medicine
DeleteIt is very interesting!
ReplyDeleteThis is a very useful article and desperately useful
ReplyDeleteI wonder whether it would be a legitimate way to assess "observed power" of an experiment by assuming a desired effect size?
ReplyDeleteWhat I mean by this: Say that I want to see whether a null finding might stem from a lack of power. I could define a desirable effect size that I want to be able to detect and compute power to observe such an effect given the sample size, alpha level and experimental design of the study. Would it be valid to reason that "we did not find a significant effect, even though we had a power of .95 to find an effect of size d = 0.25, therefore we assume that the nonsignificant finding is not the result of lacking power"?
It's not the best approach - you want to use equivalence testing. I explain why in detail here: https://osf.io/preprints/psyarxiv/97gpc/
DeleteYes both, rather belatedly(!!) I think there is a misunderstanding here, due to the language of stats! On reading your blog I realised I would be mis-using the term "post-hoc power". For me, when I read a study that reports no effect, then I may sceptically do a power analysis on that data, I would be doing exactly this: (as Dr Anon says) Calculating power given the SD of the study, but an effect size of something I would have a priori considered biologically important. ie, the starting mean and the SD may come from the studies data, but the "D" would certainly not. So in the code, perhaps just replace the D with your a priori effect size, as you allude at the bottom of the blog. I expect that would be what an editor would mean, although I have never actually seen that requested! What would this be called? obviously not "post hoc power". I can't think anyone really meant to use both means (i.e., "D") and the SDs from the actual study? That would be decidedly silly.
DeleteIndeed non-inferiority and equivalence is an alternative approach, but reading someone else's study of course you won't have the raw data do do that. I guess you can do it from means and SDs? I would be interested to read a blog on equivalence vs power calculated with an a priori D. In my field, I have never seen equivalence tests used, which is strange.
Very nice blog! I have a question!
ReplyDeleteI have two independent groups. I have looked at the means of these of two groups and ran t-tests to detect significant differences between them, but there were not any to be found. I have not done anything experimental, it is an observational/comparing/cross sectional (don't know what to call it) study. Now I am asked to run a post hoc power analysis (power analysis wasnt done before because of a new field and lack of data) to see if it was even possible for me to detect any reasonable differences with my number of observations?
Does this make sense? How could I do this? Is effect size even necessary in studies that are not experimental?
/Thom, frustrated bsc-student
(1) Effect size is useful irrespective of whether the study is experimental or not as it applies to the result and not the methodology of research. (2) Effect size is useful for accepting positive results. (3) I do not have experience to comment on its role in negative results. Post-hoc power analysis of negative result usually produces very low power when
Deletesample size is modest ( note that I did nor say small). In our genetics case-control study we found negative result with a sample of 100 per group. Result may not change even if we repeat it with say 1000 cases. But how do we establish this statistically. In another project, we found negative result with first 30 samples but positive result after analyzing 100 samples.
Interesting points!
ReplyDeleteBut, and if the editor is requesting a power analysis because he/she considers that your sample size are too small, and then that the significant differences you found using ANOVA might not be trustful?
I think there are some forms of post-hoc power analyses that are appropriate.
ReplyDeleteI agree wholeheartedly with everything you have said. Calculating the power of the study from the sample size (and SD) the alpha and the *observed* power is completely useless post-hoc.
However, would it not be reasonable for the editor to ask for the following:
In cases where a power/sample size calculation has not been performed in the original paper (perhaps in cases where group sizes are determined by other factors), would it not be suitable for the editor to ask for a calculation of the *detectable* difference. i.e put into the power calculation the alpha, sample size, a pre-agreed beta value and see what size of difference the study would have been able to fix.
I understand that this method would closely align with confidence intervals. However, I think it will demonstrate under-powered studies with more impact. Particularly in non-inferiority trials that claim non-inferiority when that are massively under-powered.
Yes, you can always calculate the effect size you could detect with a certain level of power. But, there is never information that goes beyond the p-value. So, knowing how sensitive your design was is always good info to have, but it is difficult to use it as a way to draw inferences from data.
DeleteGelman nails it down: "t’s fine to estimate power (or, more generally, statistical properties of estimates) after the data have come in—but only only only only only if you do this based on a scientifically grounded assumed effect size. One should not not not not not estimate the power (or other statistical properties) of a study based on the “effect size observed in that study.”
ReplyDeletehttps://statmodeling.stat.columbia.edu/2018/09/24/dont-calculate-post-hoc-power-using-observed-estimate-effect-size/
I know that editorials are mass-produced, including similar criticisms.
ReplyDeleteHowever, I don't know anyone who showed "how can I calculate post-hoc power" in the case of Welch's t-test, especially when the sample sizes of the two groups are different.
I'm asking to show it in a calculation code or mathematical formula in following community but,...
https://stats.stackexchange.com/questions/430030/what-is-the-post-hoc-power-in-my-experiment-how-to-calculate-this
Our reviewer's comment is this: The authors should provide a back-to-the envelope assessment of what is the power of the tests given the sample size (a classic reference to look at would be Andrews, Donald W. K. 1989. “Power in Econometric Applications.” Econometrica 57(5):1059–1090). Are you familiar with this approach? It is talking about an inverse power function. Thank you
ReplyDeleteThanks for this informative blog post. I fully agree on the nonsense of an observed power analysis with the effect size estimated from the current data. However, as you state later, a post-hoc power analysis based on an effect size of theoretical interest can be very useful. In the case of cognitive modeling, the data points going into estimation of conditional parameters further back in the model crucially depend on the level of performance achieved in earlier processes and thus cannot be estimated a priori. Here, a post-hoc power analysis based on the level of performance achieved in prior parameters and then asking whether meaningful, theoretically predicted differences in further back parameters would have been observed with sufficient power is the only informative power analysis that can be conducted. I would greatly appreciate if you could clarify that post-hoc power analysis is more than observed power analyses and that this rightful critique only concerns a specific subset of post-hoc power analyses referred to as observed power analysis. Thank you.
ReplyDeleteThis comment has been removed by a blog administrator.
DeleteThis comment has been removed by a blog administrator.
ReplyDeleteThis comment has been removed by a blog administrator.
ReplyDeleteThis comment has been removed by a blog administrator.
ReplyDeleteThis comment has been removed by a blog administrator.
ReplyDeleteThis comment has been removed by a blog administrator.
ReplyDeleteThis comment has been removed by a blog administrator.
ReplyDeleteThis comment has been removed by a blog administrator.
ReplyDeleteThis comment has been removed by a blog administrator.
ReplyDeleteThis comment has been removed by a blog administrator.
ReplyDeleteThis comment has been removed by a blog administrator.
ReplyDeleteThis comment has been removed by a blog administrator.
ReplyDeleteThis comment has been removed by a blog administrator.
ReplyDeleteThis comment has been removed by a blog administrator.
ReplyDeleteThis comment has been removed by a blog administrator.
ReplyDeleteThis comment has been removed by a blog administrator.
ReplyDeleteThis comment has been removed by a blog administrator.
ReplyDeleteThis comment has been removed by a blog administrator.
ReplyDeleteThis comment has been removed by a blog administrator.
ReplyDeleteThis comment has been removed by a blog administrator.
ReplyDeleteThis comment has been removed by a blog administrator.
ReplyDeleteThis comment has been removed by a blog administrator.
ReplyDeleteThis comment has been removed by a blog administrator.
ReplyDeleteThis comment has been removed by a blog administrator.
ReplyDeleteThis comment has been removed by a blog administrator.
ReplyDeleteThis comment has been removed by a blog administrator.
ReplyDelete