In a recent FiveThirtyEight article, a statistical approach known as magnitude based inferences, popular in sports sciences, was severely criticized. Critically evaluating approaches to statistical inferences is important. In my own work on statistical inferences, I try to ask myself whenever a problem is identified: "So how can I improve?". In this blog, I'll highlight 3 ways to move beyond magnitude based inferences, achieving the same goals, but with more established procedures. I hope sport scientists in doubt of how to analyze their data will learn some other approaches that are less contested, but equally useful.
The key goal in magnitude based inferences
is to improve upon limitations of null-hypothesis significance tests. As
Batterham & Hopkins (2006) write: “A confidence interval alone or in
conjunction with a P value still does not overtly address the question of the
clinical, practical, or mechanistic importance of an outcome.” To complement
p-values and confidence intervals, they propose to evaluate confidence
intervals in relation to two thresholds, which I prefer to call the ‘smallest
effect size of interest’.
Magnitude Based Inference
Although I’m not a particularly sporty person,
I recently participated in the Rotterdam City Run, where we ran through our
beautiful city, but also through the dressing room of a theater, around an
indoor swimming pool, a lap through the public library, and the fourth story of
a department store. The day before the run, due to train problems I couldn’t
get to work, and I wasn’t able to bring my running shoes (which I use at the
university sport center) home. I thought it would be OK to run on sneakers,
under the assumption ‘how bad can it be’? So let’s assume we examine the amount
of physical discomfort people experience when running on running shoes, or on
normal sneakers. As we discuss in Lakens, McLatchie, Isager, Scheel, &
Dienes (under review), Kelly (2001) reports that the smallest effect size that
leads to an individual to report feeling “a little better” or “a little worse”
is 12 mm (95% CI [9; 12]) on a 100 mm visual analogue scale of pain intensity.
So let’s say I would have been fine with running on sneakers instead of real
running shoes if after the run I would be within 12 mm of the pain rating I
would have given on good running shoes. In other words, I consider a 12 mm
difference trivial – sure, I didn’t have my running shoes, but that’s a trivial
thing when going on a city run. I also leave open the possibility that my
running shoes aren’t very good, and that I might actually feel better after running on my normal
sneakers – unlikely, but who knows.
In formal terms, I have set my equivalence
bounds to a difference of 12 mm when running on sneakers, or when running on
decent running shoes. All differences within this equivalence range (the light
middle section in the figure below, from Batterham and Hopkins, 2006) are considered
trivial. We see the inferences we can draw from the confidence interval
depending on whether the CI overlaps with the equivalence bounds. Batterham and
Hopkins refer to effects as ‘beneficial’ as long as they are not harmful. This
is a bit peculiar, since from the third confidence interval from the top, we can
see that this implies calling a finding ‘beneficial’ when it is not
statistically significant (the CI overlaps with 0), a conclusions we would not
normally draw based on a non-significant result.

Batterham and Hopkins suggest to use verbal
labels to qualify the different forms of ‘beneficial’ outcomes to get around
the problem of simply calling a non-significant result ‘beneficial’. Instead of
just saying an effect is beneficial, they suggest labeling it as ‘possible
beneficial’.

Problems with Magnitude Based Inference
In a recent commentary, Sainani (2018) points
out that even though the idea to move beyond p-values and confidence intervals
is a good one, magnitude based inference has problems in terms of error
control. Her commentary was not the first criticism raised about problems with
magnitude based inference, but it seems it will have the greatest impact. The (I
think somewhat overly critical) article on FiveThirtyEight
details the rise and fall of magnitude based inference. As Sainani summarizes: “Where
Hopkins and Batterham’s method breaks down is when they go beyond simply making
qualitative judgments like this and advocate translating confidence intervals
into probabilistic statements such as: the effect of the supplement is ―very
likely trivial or ―likely beneficial”
Even though Hopkins and Batterham (2016)
had published an article stating that magnitude based inference outperforms
null-hypothesis significance tests in terms of error rates, Sainani shows
conclusively that this is not correct. The conclusions by Hopkins and Batterham (2016) were based on an incorrect
definition of Type 1 and Type 2 error rates. When defined correctly, the Type 1
error rate turns out to be substantially higher for magnitude based inferences
(MBI) depending on the smallest effect size of interest that is used to define
the equivalence bounds (or the ‘trivial’ range) and the sample size (see Figure
1G below from Sainani, in press). Note that the main problem is not that error rates are always higher (as the graphs shows) - just that they will often be, when following the recommendations by Batterham and Hopkins.

How to Move Forward?
The idea behind magnitude based inference is
a good one, and not surprisingly, statisticians had though about exactly the
limitations of null-hypothesis tests and confidence intervals that are raised
by Batterham and Hopkins. The idea to use confidence intervals to draw
inferences about whether effects are trivially small, or large enough to
matter, has been fully developed before, and sport scientists can use these more established methods. This is good news for people working in sports
and exercise science who want to not simply fall back to null-hypothesis tests
now that magnitude based inference has been shown to be a problematic approach.
Indeed, in a way it is surprising Batterham
and Hopkins never reference the extensive literature to approaches that are on
a much better statistical footing than magnitude based inference, but that are
extremely similar in their goal.
The ROPE procedure
The first approach former users of
magnitude-based inference could switch to is the ROPE procedure as suggested by
John Kruschke (for an accessible introduction, see https://osf.io/s5vdy/). As pointed out by
Sainani, the use of confidence intervals by Batterham and Hopkins to make
probability judgments about the probability of true values “requires
interpreting confidence intervals incorrectly, as if they were Bayesian credible
intervals.” Not surprisingly, one solution moving forward for exercise and
sports science is thus to switch to using Bayesian credible (or highest
density) intervals.
As Kruschke (2018) clearly explains, the
Bayesian posterior can be used to draw conclusions about the probability that
the effect is trivial, or large enough to be deemed beneficial. The similarity
to magnitude based inference should be obvious, with the added benefit that the
ROPE procedure rests on a strong formal footing.

Equivalence Testing
One of the main points of criticism on
magnitude based inference demonstrated conclusively by Sainani (2018) is that
of poor error control. Error control is a useful property of a tool to draw
statistical inferences, since it will guarantee that (under certain
assumptions) you will not draw erroneous conclusions more often that some
threshold you desire.
Error control is the domain of Frequentist
inferences, and especially the Neyman-Pearson approach to statistical
inferences. The procedure that strongly mirrors magnitude based inferences from
a Frequentist approach to statistical inferences is equivalence testing. It
happens to be a topic I’ve worked on myself in the last year, among other
things creating an R package (TOSTER) and writing tutorial papers to help
psychologists to start using equivalence tests (e.g., Lakens, 2017, Lakens, Isager,
Scheel, 2018).
As the Figure below (from an excellent
article by Rogers, Howard, & Vessey, 1993) shows, equivalence tests also
show great similarity with magnitude based inference. It similarly builds on
90% confidence intervals, and allows researchers to draw similar conclusions as
magnitude based inference aimed to do, while carefully controlling error rates.

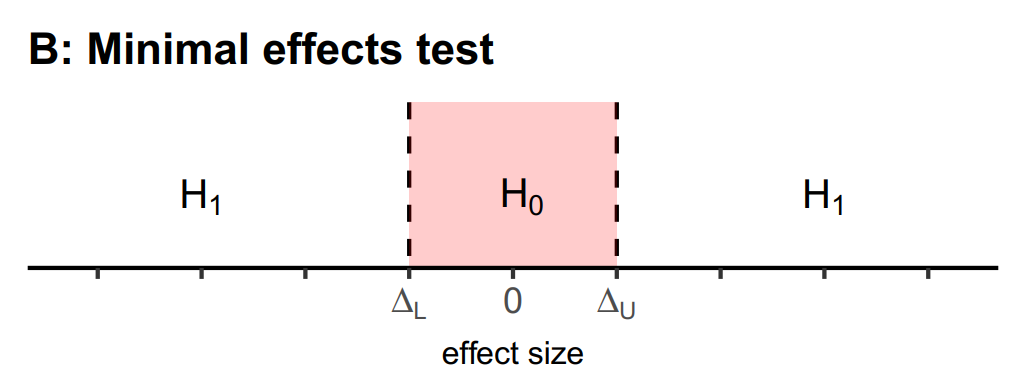
Minimal Effect Tests
Another idea in magnitude based inference
is to not test against the null, but to test against the smallest effect size
of interest, when concluding an effect is beneficial. In such cases, we do not
want to simply reject an effect size of 0 – we want to be able to reject all
effects that are too small to be trivial. Luckily, this also already exists,
and it is known as minimal effect testing. Instead of a point null hypothesis,
a minimal effects test aims to reject effects within the equivalence range (for
a discussion, see Murphy & Myors, 1999.
Conclusion
There are some good suggestions underlying
the idea of magnitude based inferences. And a lot of the work by Batterham and
Hopkins has been to convince their field to move beyond null-hypothesis tests
and confidence intervals, and to interpret the results in a more meaningful
manner. This is a huge accomplishment, even if the approach they have suggested
lacks a formal footing and good error control. Many or their recommendations
about how to think about which effects in their field are trivial are extremely
worthwhile. As someone who has worked on trying to get people to improve their statistical
inferences, I know how much work goes into trying to move your discipline
forward, and the work by Batterham and Hopkins on this front has been extremely worthwhile.
At this moment, I think the biggest risk is
that the field falls back to only performing null-hypothesis tests. The ideas
underlying magnitude based inferences are strong, and luckily, we have the ROPE
procedure, equivalence testing, and minimal effect tests. These procedures are
well vetted (equivalence testing is recommended by the Food and Drug Administration)
and will allow sports and exercise scientists to achieve the same goals. I hope
they will take all the have learned from Batterham and Hopkins about drawing
inferences by taking into account the effect sizes predicted by a theory, or that
are deemed practically relevant, and apply these insights using the ROPE
procedure, equivalence tests, or minimal effect tests.
P.S. Don't try to run 10k through a city on sneakers.
References
Batterham, A. M., & Hopkins, W. G. (2006). Making Meaningful
Inferences About Magnitudes. International Journal of Sports Physiology and
Performance, 1(1), 50–57. https://doi.org/10.1123/ijspp.1.1.50
Hopkins, W. G., & Batterham, A. M. (2016). Error Rates, Decisive
Outcomes and Publication Bias with Several Inferential Methods. Sports
Medicine, 46(10), 1563–1573. https://doi.org/10.1007/s40279-016-0517-x
Kruschke, J. K. (2018). Rejecting or Accepting Parameter Values in
Bayesian Estimation. Advances in Methods and Practices in Psychological
Science, 2515245918771304. https://doi.org/10.1177/2515245918771304
Lakens, D., Scheel, A. M., & Isager, P. M. (2017). Equivalence
Testing for Psychological Research: A Tutorial. PsyArXiv. https://doi.org/10.17605/OSF.IO/V3ZKT
Lakens, D. (2017). Equivalence Tests: A Practical Primer for t
Tests, Correlations, and Meta-Analyses. Social Psychological and Personality
Science, 8(4), 355–362. https://doi.org/10.1177/1948550617697177
Lakens, D., McLatchie, N., Isager, P. M., Scheel, A. M., &
Dienes, Z. (2018). Improving Inferences about Null Effects with Bayes Factors
and Equivalence Tests. PsyArXiv. https://doi.org/10.17605/OSF.IO/QTZWR
Murphy, K. R., & Myors, B. (1999). Testing the hypothesis that
treatments have negligible effects: Minimum-effect tests in the general linear
model. Journal of Applied Psychology, 84(2), 234.
Sainani, K. L. (2018). The Problem with “Magnitude-Based Inference.”
Medicine & Science in Sports & Exercise, Publish Ahead of Print. https://doi.org/10.1249/MSS.0000000000001645
Great article Daniel!!!
ReplyDeleteThe recommendations in this blog post appear to be based on the assumption that a large initial study will be conducted when researchers do not have a clear prediction about an effect. This strategy is feasible when resources are available for large projects. However, if resources are limited, smaller initial exploratory studies may be useful to justify the greater resources for a large study. This is a common situation in medical research, which often requires expensive specialized measurements and a selected pool of subjects. From this perspective, magnitude based inferences might be a useful exploratory method to evaluate whether a larger confirmatory study is justified. In general, any discussion of statistical research methods that does not distinguish between exploratory and confirmatory research and describe how and whether the methods apply to each stage of research will likely encourage continued blurring of exploration and confirmation and continued misuse of statistics.
ReplyDeleteThe recommended methods appear to be useful in initial studies when researchers do not have clear predictions, but the methods may not be widely useful for confirmatory research. If the research question is practical such as whether a certain type of shoe, or educational program, or medical treatment is better or worse than another, then it is reasonable that the researchers initially do not have a clear prediction and will use two-sided tests (although the sponsor of the research probably has a preferred outcome).
However, when the research questions are more theoretical, a two-sided test usually means the researchers do not have a clear theoretical prediction and want to have the flexibility to make up an explanation after looking at the results. Such post hoc explanations are often not distinguished from pre-specified theory given that the planned statistical analysis was significant. Science is based on making and testing predictions. Two-sided tests are usually the exploratory stage of research without a clear theoretically-based prediction.
The extreme case is when the only prediction is that the effect size is not zero, as has been common in psychological research in recent decades. This prediction is not falsifiable in principle because any finite sample size may have inadequate power to detect the extremely small effects consistent with the hypothesis. Without a smallest effect size of interest, research is not falsifiable.
The confirmatory research that is needed to make science valid and self correcting will usually be based on one-sided statistical tests with falsifiable predictions. Unfortunately statistical methods for conducting falsifiable research with classical (frequentist) statistics have not been widely known among psychological researchers. Such methods are described in a paper at
https://jeksite.org/psi/falsifiable_research.pdf .
Hi Jim, the methods described in the blog are perfectly suited for confirmatory research. One-sided versions of equivalence tests exist (non-imferioritybtests, as explained in my papers). Thanks for the link to your pdf - it does contain some errors and outdated adice (see criticism on the 'power approach' in my equivalence testing papers - you might want to read the latest paper to improve your understanding of equivalence tests.
DeleteHi Daniel,
ReplyDeleteI was wondering why this post, seemingly goes against what Hopkins and peers recommend on his peer reviewed website
https://sportscience.sportsci.org/2020/index.html
Even though here it seems like you were happy with the method outlined in sportsscience.sportssci.
https://discourse.datamethods.org/t/what-are-credible-priors-and-what-are-skeptical-priors/580/22
This comment has been removed by a blog administrator.
ReplyDeleteThis comment has been removed by a blog administrator.
ReplyDeleteThis comment has been removed by a blog administrator.
ReplyDeleteThis comment has been removed by a blog administrator.
ReplyDeleteThis comment has been removed by a blog administrator.
ReplyDeleteThis comment has been removed by a blog administrator.
ReplyDelete